

What is Tail Spend?
Just like in spend data classification, the definition of tail spend is subjective. Some organisations classify tail spend at the bottom 20% of spend, while others might set a financial level such as £100,000 or £1 million.
According to CIPS, tail spend “can often be referred to as rogue spend or maverick spend, is usually small value purchases that are conducted by the organisations outside of a contract and often outside of the awareness of the procurement team.”
But that’s a bit wordy for me and if you’ve read any of my other Future of Sourcing articles you’ll know I like to explain things in plain and simple terms. So, to put it very simply, tail spend is all those low value, fiddly suppliers that you’ve probably only ever used once and will probably never use again.
The best way to really explain it is to visualise it, mainly because it actually looks like a tail.
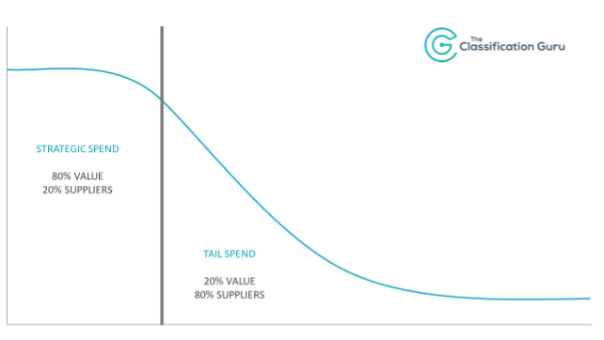
So, why is tail spend such a problem?
Well first of all, there’s generally a lot of it. Even though it’s only 20% of spend, it can be thousands or hundreds of thousands of rows of data. Who has time to deal with that, right? When you’re struggling to manage the strategic 80%, how valuable is it to use your time classifying a line for £1.50? However, it’s important to manage tail spend because today’s tail spend could be tomorrow’s strategic spend.
Imagine a scenario where you only classify your data every six months and you last classified your data a month or two before year-end, and you also have a new supplier who has a value of £100,000.
It falls into tail spend, but over the next six months this new supplier becomes a strategic supplier. Except no one has picked up that this spend is not being classified.
Is it the end of the world? No.
But could the wrong decisions be made because the right information wasn’t available? Absolutely.
So, what’s the solution?
Well, there’s no easy or quick fix. The “easiest” option is to outsource it, but how is it being classified by the third party supplier? Is it automated? Is a team doing it? If so, how experienced are they? And are they classifying 100% of the data? It’s hard to know.
I know many suppliers will classify 90% to 95% of the value, but that can still leave hundreds or thousands of lines unclassified. And the truth is because it’s small value items in the large scheme of things, it could be wrong but no one is checking. What if that tail spend is tomorrow’s strategic spend?
Another option is to manage this in-house. This requires a lot of time, patience, attention to detail and thoroughness, but the reality is most people are already overloaded with higher priority tasks.
It’s not a great solution.
Then there’s third party suppliers. Will it cost you? Of course it will, but it’s and investment, and let’s face it your team probably don’t have the time to do it. Let’s think about it this way… yes, you could wash your car yourself but wouldn’t you rather have it hand valeted? Absolutely.
Plus, you will more than recoup the costs of the classification through spend analytics when you have your shiny new data set back… suddenly supplier rationalisation, spend visibility and cost savings become much easier!
But that’s not enough…
The secret to keeping your data clean and keeping track of your tail spend isn’t really a huge secret, it’s really a case of good housekeeping!
You need to check and maintain it regularly. In the same way you give your carpets a regular once-over with the vacuum, regularly checking in with your data makes life easier in the long run.
And, just like a weekly or twice weekly vacuum around the house, it’s a good idea to check in on your data on a monthly or quarterly basis.
This is still just as important even if you have a third-party supplier checking over your data. You should still spot-check your data once in a while to ensure your supplier is fulfilling their obligations.
And, if your team is running the checks for you, make sure you check in with their progress once in a while to make sure everyone’s on board with the same standards and cleaning the data in the same way. It’s also a good opportunity for highlighting development areas for your team.
So, how frequently should you check your data?
Let’s go back to that carpet analogy. Leaving your carpet for a week doesn’t matter. It doesn’t really matter if you leave it for a month (as long as you’re okay with living with dirty carpets). But leave that once fresh and spotless carpet too long and by the time you pull out your vacuum cleaner, your carpet will be beyond saving.
It’s the same with your data. Data that is not maintained will slowly become unusable over time. Incorrect or conflicting information will build up. AI outputs become corrupted. And because you can’t afford to use bad data, you end up spending significant time or money to fix the problem. Ouch.
Regular data maintenance means:
- Better data accuracy for better business decisions.
- Avoiding a time-consuming and costly data clean-up operation (because your data won’t slowly become corrupted).
- A better-trained and more responsive data team. Doing a little bit of something regularly is always easier than doing a lot of it occasionally.
- An informal opportunity to stay in touch with the work your third-party supplier is doing.






